UX++ and DX++ with Sync Engines
We're stuck at improving our web apps UX. What we do currently is too complex for devs. I am certain that Sync Engines are the next leap forward for both creating magical user experiences and reducing mental load for developers.
Disclaimer: This was originally a talk I gave on the first Munich TypeScript Meetup I organized.
Application data lives on the server. The server will be the data authority for the foreseeable future. Having clients talk to a common server is how we build apps with multiple users. It’s how we enable API access to our apps. Even single user applications need a server for syncing data across devices.
But dealing with remote state is a source of complexity and pain when aiming for good UX and DX.
Let me explain
Have you written code like this?
function Todos() { const { data, isLoading, isError } = useQuery(["todos"], fetchTodos)
if (isLoading) return <p>😴 Wait for it...</p>
if (isError) return <p>‼️ Dang!</p>
return ( <ul> {data.map(todo => ( <li key={todo.id}>✅{todo.title}</li> ))} </ul> )}A classic. Fetching todos from a server. Handling loading and error states and finally display the todo list. But fetching data is not everything. When we implement mutations it looks roughly like this:
function AddTodo() { const mutation = useMutation(addTodo)
function handleAddTodo() { mutation.mutate({ title: "New Todo" }) }
return ( <button onClick={handleAddTodo}> {mutation.isLoading ? "😴..." : "Add Todo"} </button> )}These examples use TanStack Query. An awesome library for asynchronous state management. It’s the de facto standard for fetching data in modern UI development. With TanStack Query we can build data-aware components. Reusable blocks that encapsulate data requirements, mutations and UI.
This is a good pattern for DX, but the default UX is suboptimal.
Chaining Loading States
if (isLoading) return <p>😴...</p>if (isError) return <p>Dang! 🤦♂️</p>return <AnotherComponentWithQuery />Loading states provide immediate feedback to user action. The idea is to make our app respond faster to user input. But we introduce branching into our UI tree. The network waterfalls we create multiply the network latency by the nesting depth.
This is how modern web apps replace spinners with other spinners and then more spinners. Sometimes it takes seconds after a website is fully loaded.
Stale Data, unless manually invalidated
const mutation = useMutation(addTodo, { onSuccess: () => { // 🤯 invalidate all keys? queryClient.invalidateQueries()
// 🤔 what keys to invalidate? queryClient.invalidateQueries({ queryKey: ["todos"], }) },})TanStack Query caches query results by default. And without further action we show stale data by default. But we can invalidate the cache, right?
Sure! Manually.
Invalidating queries is only half the battle. Knowing when to invalidate them is the other half. Usually when a mutation in your app succeeds, it’s VERY likely that there are related queries in your application that need to be invalidated and possibly refetched to account for the new changes from your mutation.
— TanStack Query Docs
We can make our lives easy by invalidate, or better delete all query keys, making potentially unnecessary refetches. Or we need to be smart about what keys to invalidate.
But then we need to know all keys affected by each mutation. Otherwise parts of our UI continue showing stale data.
Optimistic UI
UX can be further improved with Optimistic UI. We assume a successful query and manually manipulate the cache to include the assumed result even before the server responds with new data.
const mutation = useMutation(addTodo, { onMutate: async (newTodo) => { const previousTodos = queryClient.getQueryData(...); queryClient.setQueryData([newTodo, ...previousTodos]); return { previousTodos }; }, onError: (_, _, context) => { queryClient.setQueryData(["todos"], context.previousTodos); }, onSettled: () => { queryClient.invalidateQueries(["todos"]); },});To effectively implement Optimistic UI, we need to know all affected query keys and the effect of each mutation on them.
Imagine you add another query in your UI. How do you make sure every mutation appropriately invalidates this query or injects correct data for Optimistic UI, if it affects this new query?
You see where I am going with this.
But there’s more:
- Server Side Rendering: the UI code now runs in Node and in the Browser. Hydration Errors, Window is not defined, Node libraries being bundled to the browser…
- Progressive Enhancement: Server rendered React Apps rely on JS to be interactive. Users may tap on unresponsive UI. To have the app work without JS, you need to implement the app differently.
- Edge Runtimes: UI code now runs in Node, the Browser and an Edge Runtime with another set of rules.
- React Server Components: The UI code that runs in different places now has different rules.
All this is more complexity, more mental load, more to learn, more to get wrong when building modern web applications.
When you grew up with these techniques, each step kinda makes sense. Each evolution tackles an existing issue. You learn one more thing and have one less problem. But how do we explain this to new developers?
We are building waiting experiences
Much time, energy and complexity is spend on improving the problem inherent in having state on the server and the app on the client. In the seek of performance, we are treating symptoms instead of fixing the root cause.
We make to many requests that require our users to wait before they can proceed.
We can’t control the network. But the network controls our app experience. It doesn’t matter how much framework we throw at this problem. We need to rethink how data flows between client and server.
And there is no further room for improvements. UI renders sufficiently fast. Servers can respond with cached data. But receiving any response takes a few hundred milliseconds unless you happen to live close to one of the two or three major data centers.
Rethink Dataflows: Sync Engines
A sync engines main purpose is to eliminate the network roundtrip from the critical part of an application. The essential idea is to have a local copy of the data on the client. UI components subscribe to or mutate local data while the engine syncs changes with the server in the background.
There are plenty of approaches. localfirstweb.dev is a great resource for available libraries, talks, blog posts. The sync engine that immediately clicked for me was Replicache.
Replicache
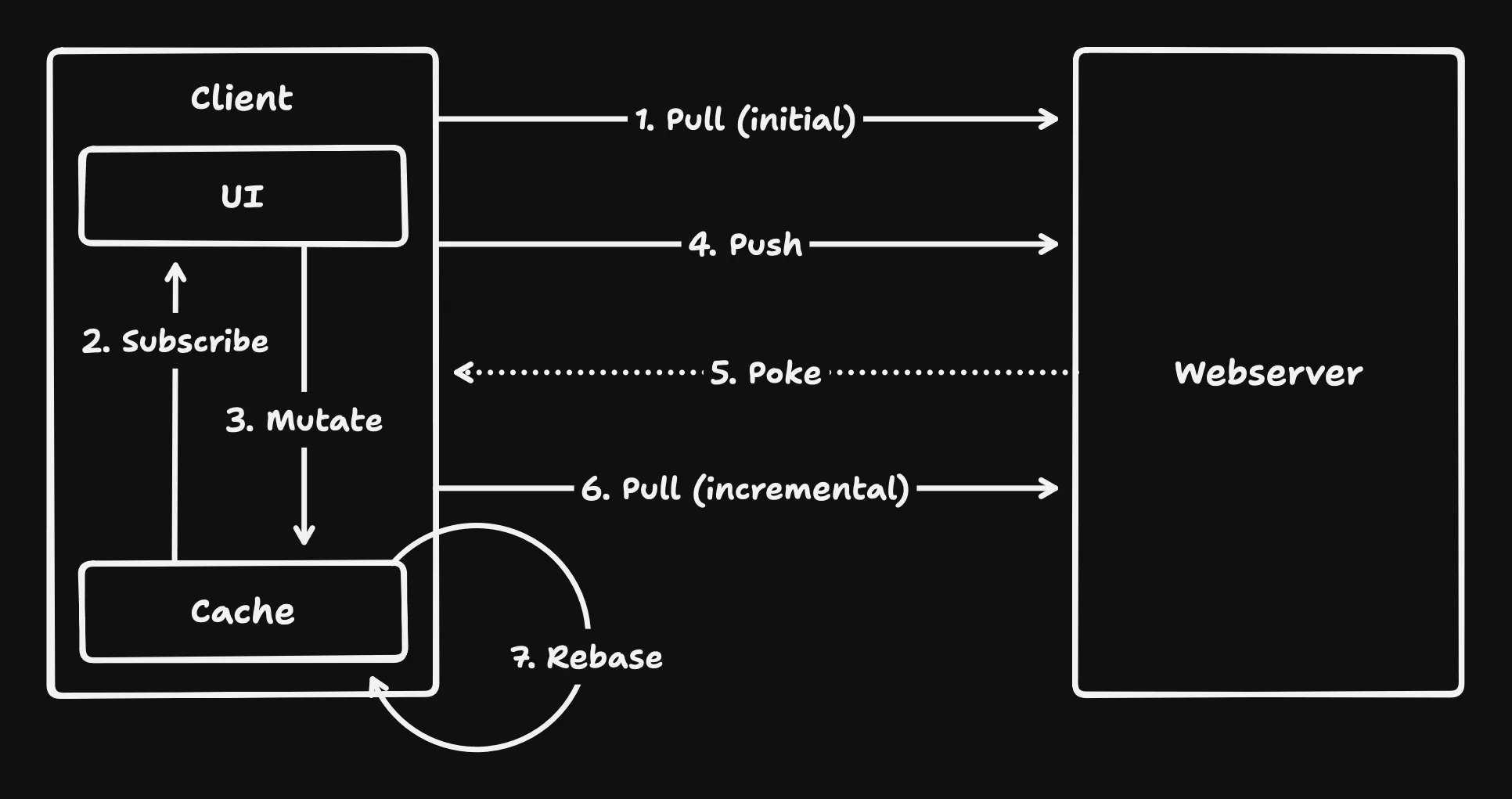
Replicache is a key-value store that works like git. The best part is that it is as thin as a sync engine can get. It only runs in your client, provides subscription and mutation methods and communicates with API endpoints that you implement, keeping you in control of your server, your database, your business logic. Once set up, it effectively replaces TanStack Query and a RPC.
The process of a Replicache powered app is:
- You identify the user and initialize Replicache for this user in the client
- Replicache performs an initial pull request, populating the cache
- UI components subscribe to data in the cache
- Actions in your UI can trigger mutations
- Mutations are pushed to your server in the background
- The server can send poke notifications to clients
- Incremental pulls are performed periodically, manually or on poke events
- Cache updates received on pull requests are merged into the local cache
Let’s go through the steps with more detail.
Pull
// initial{ patch: [ { op: "clear" }, { op: "put", key: "todo/abc123", value: { id: "abc123", title: "Learn Replicache", completed: false } }, ... // more todos, or other data ]}// incremental update{ patch: [ { op: "put", key: "todo/abc123", value: { id: "abc123", title: "Learn Replicache", completed: true } }, { op: "delete", key: "todo/other-todo" } ]}You implement the pull endpoint yourself. The pull endpoint returns instructions to the client on what data to put into the cache. You decide, what data to send.
A record of key-version pairs is stored on the server, called Client View. The Client View is diffed on consecutive pulls from the same client to send incremental updates. You can decide on which level of detail you track the client view. Read the Replicache docs on Backend Strategies.
The Replicache client stores this data persistently in the browser.
Subscribe
function Todos() { const todos = useSubscribe(rep, async tx => { return await tx.scan({ prefix: "todo/" }).toArray() }) return ( <ul> {todos.map(todo => ( <li key={todo.id}>✅ {todo.title}</li> ))} </ul> )}Instead of querying data directly from the server, you subscribe to local data from Replicache. Subscriptions resolve instantly. Replicache takes care of updating the UI when the underlying data changes. It doesn’t matter if the data changes because of local mutations or fresh data from the server. UI updates are triggered when the query result changes.
Mutate
function AddTodo() { function handleAddTodo() { return rep.mutate.addTodo({ id: nanoid(), title: "Be nice on X" }) }
return <button onClick={handleAddTodo}>Add Todo</button>}Mutations are applied to the local cache by your own local implementation. The UI updates immediately where this data is displayed, thanks to subscriptions. Mutations are queued persistently and sent to the push endpoint of your server in the background.
Push
// on your serverasync function handlePush(request: PushRequest, user: User) { for (const mutation of request.mutations) { await processMutation(mutation, user, request.clientGroupID) }}The push endpoint receives ordered mutations from the client. Your implementation applies these mutations one by one on the server state. This is where your custom business logic takes over. In case of network failures Replicache retries sending mutations to the server.
You keep track of the mutations that you applied from each client to inform clients on the next pull. This way clients apply pending mutations on pulled data.
It’s like React, but for Data
React is complex but it absorbs complexity so we can write simpler programs, by introducing the component model and an unidirectional data flow.
In a similar way Replicache introduces the idea of syncing your data with a push and pull model, like Git. It allows us to write simpler programs that have unmatched user experience.
But why is the code simpler? It’s because we subscribe to and mutate local data. This way, we can have great UX by default:
- Instant UI: Navigations happen instantly. Users see results of their actions immediately. No spinners.
- Offline Capable: The network speed can be 0 and users won’t notice. Data is synced as soon as the app is online.
- Easy on Bandwidth: The initial pull is large, but then we receive incremental updates.
- Realtime Collaboration: Push, poke, incremental pull. Realtime collaboration is a natural extension.
Raise the bar for UX, not mental load
The frame rate is the limit for web apps built with sync engines. They are absorbing the complexity at the network layer. Frontend developers can build new features on top of local data. And the UX is magical.
Please try this at home.